
爬虫篇:爬小刀娱乐网-绿色软件-办公学习数据(附代码)

前言:Python 爬虫(Web Scraping)是一种自动化地从网站提取数据的技术。下面我将给出一个简单的 Python 爬虫示例(以小刀娱乐网-绿色软件-办公学习模块为例,站长本人如果看见,如有冒犯,请联系删除,代码仅供学习,请勿用于违法行为!),该爬虫将使用 requests 库来发送 HTTP 请求,并使用 BeautifulSoup 库来解析 HTML 页面,从而抓取一个网页上的所有文章标题,文章详情,下载地址,并使用csv库将数据写入csv文件里。
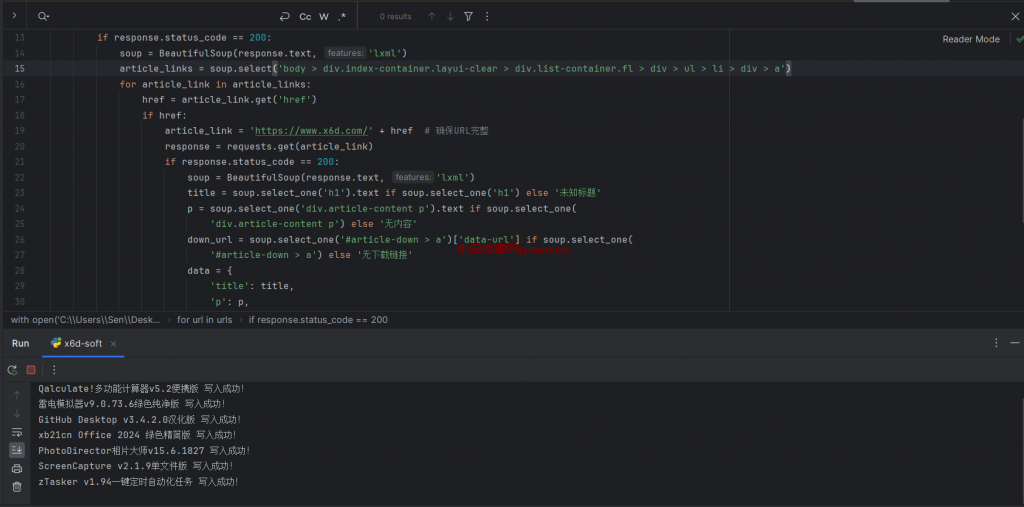
import requests
from bs4 import BeautifulSoup
import csv
with open('C:\\Users\\Sen\\Desktop\\小刀娱乐网-绿色软件-办公学习.csv', 'w', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=['title', 'p', 'down_url'])
writer.writeheader()
base_url = 'https://www.x6d.com/html/26-{}.html'
urls = [base_url.format(i) for i in range(1, 34, 1)]
for url in urls:
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'lxml')
article_links = soup.select('div.list-container.fl li div a') # 简化选择器
for article_link in article_links:
href = article_link.get('href')
if href:
article_link = 'https://www.x6d.com/' + href # 确保URL完整
response = requests.get(article_link)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'lxml')
title = soup.select_one('h1').text if soup.select_one('h1') else '未知标题'
p = soup.select_one('div.article-content p').text if soup.select_one(
'div.article-content p') else '无内容'
down_url = soup.select_one('#article-down > a')['data-url'] if soup.select_one(
'#article-down > a') else '无下载链接'
data = {
'title': title,
'p': p,
'down_url': down_url
}
writer.writerow(data)
print(title + ' 写入成功!')
else:
print(f"请求 {article_link} 失败,状态码: {response.status_code}")
else:
print("无有效的链接")
else:
print(f"请求 {url} 失败,状态码: {response.status_code}")
写入csv文件的数据
微信扫描下方的二维码阅读本文

版权声明:
作者:admin
链接:https://q-sen.cn/%e6%8a%80%e6%9c%af%e6%96%87%e7%ab%a0/%e7%88%ac%e8%99%ab%e7%af%87%ef%bc%9a%e7%88%ac%e5%b0%8f%e5%88%80%e5%a8%b1%e4%b9%90%e7%bd%91-%e7%bb%bf%e8%89%b2%e8%bd%af%e4%bb%b6-%e5%8a%9e%e5%85%ac%e5%ad%a6%e4%b9%a0%e6%95%b0%e6%8d%ae%ef%bc%88%e9%99%84/.html
来源:小全资源网
文章版权归作者所有,未经允许请勿转载。
THE END
二维码
共有 0 条评论